

Accessも含めた「リレーショナルデータベース(RDB)」の大きな特徴は、データを複数のテーブルに分割し、効率的に管理できる点にあります。この効率的なデータ管理を実現するために不可欠な概念が「正規化」です。
本記事では、テーブル設計における正規化の必要性に焦点を当て、具体的な正規化の手順を解説します。
正規化の概要
データベースの正規化を一言で表現すると「データの整理整頓術」です。データをテーブルという「きちんと整理されたいくつかの箱」に分けて格納し、重複をなくし、矛盾を防ぎます。
例えば、顧客と注文の情報を管理するテーブルがあったとします。これらを1つのテーブルで管理すると、注文ごとに顧客情報を何度も入力する必要があります。何度も入力するので時には誤入力があったり、そもそも記憶容量を無駄に消費していまいます。これが重複の無駄であり、矛盾です。
このような重複の無駄や矛盾を解消する手法が正規化です。
正規化の手順
正規化には第1正規形から第5正規形までの段階がありますが、一般的には第3正規形までを適用します。今回は下記の「社員資格管理テーブル」を題材に、具体的な正規化を進めていきましょう。

上表は、ある会社の社員が保持している資格を一覧にしたものです。このテーブルには、一目でわかる問題点がいくつかあります。最も大きな問題点は、資格名と資格取得日のフィールドに、複数の資格情報がカンマ区切りで入力されていることです。
この形式でデータを管理すると、以下のようなデメリットが生じます。
Accessのテーブルでは、1レコードで1つのデータを管理するのが基本です。そのため、1つのフィールドに複数のデータを繰り返し入力する形式は避ける必要があります。そこで、第1正規形ではこれらの問題点を解消します。
第1正規形
第一正規形の目的:
同一フィールドの繰り返しデータを無くす
第1正規形では、1つのフィールド内に繰り返し入力されたデータを、1レコードにつき1データとなるよう分割します。今回の例では、社員IDが1002と1005のレコードが分割対象となります。
分割後のテーブルがこちらです。

分割したことで行が増えましたね。社員と資格の組み合わせを1レコードで管理する形式に変更し、第1正規形が完了しました。
オレンジ色が主キーです。この時点では「社員ID」と「資格名」を複合主キーとして一意のデータを特定します
第2正規形
第2正規形の目的:
主キーの一部によって決まるフィールドを別テーブルに分離する
第1正規形後のテーブルは、確かに1レコードずつ整理され見やすくなりました。しかし、データを入力する側から見ると、同じ社員IDや社員名を何度も入力する必要があり、手間がかかり、誤入力も発生しやすいという課題が残ります。この辺りの課題を解消するために、第2正規形ではテーブルの分割を行います。
併せて、現在の主キーは「社員ID」と「資格名」の複合キーですが、「資格名」は長い文字列で誤入力のリスクもあり主キーに向かないため、新規フィールドとして「資格CD」を用意して、主キーを「社員ID」と「資格CD」の組み合わせにします。
第2正規形では、主キー(「社員ID」と「資格CD」の複合キー)の一部に依存するフィールドを別のテーブルに分割します。
”主キーの一部で依存する”ってどういう意味?
今回のテーブルでいえば以下の依存関係があるよね
- 「社員ID」が決まれば「社員名」「生年月日」「年齢」「部署名」が決定される
- 「社員ID」と「資格CD」が決まれば「資格取得日」が決定される
- 「資格CD」が決まれば「資格名」が決定される
なるほど!赤書は全て主キーで、そのキーに依存するものを別テーブルに分割ってわけかぁ
さて、これらのテーブル分割をした結果をみてみましょう。

テーブルを3つに分割したことで、各テーブルは主キーによって一意に管理されるようになりました。
第3正規形
第3正規形の目的:
・主キー以外で決まるフィールドを他テーブルに分割する
・導出フィールドを削除する
第2正規形によって主キーに関連するフィールドを別テーブルに分割し、ある程度の冗長性を排除できました。しかし、「社員管理テーブル」には、まだ繰り返し入力が必要なフィールドが残っています。それは「部署名」です。主キーに直接関連しないフィールドの分割は、第3正規形で行います。
また、「年齢」フィールドは生年月日から計算で求められるため、削除対象となります。このように計算で求められるフィールドを「導出フィールド」と呼び、第3正規形ではこれらのフィールドも削除します。
さあ、これらのテーブルを分割した結果をみてみましょう。

新たに「部署CD」を設け、部署名をマスタテーブル化したことで、テーブルを適切に分割できました。
さて、正規化により元は一つのテーブルを、4つのテーブルに分割しました。
- 社員管理テーブル
- 資格取得管理テーブル
- 資格マスタテーブル
- 組織マスタテーブル
各テーブルは主キーによって一意に管理されるようになり、データの視認性が向上するとともに、手入力が不要になったことで、データ管理の効率性と信頼性も向上しました。
以上が、一般的な正規化の流れとなります。
正規化のメリットとデメリット
ひと通り手順が把握できたところで、改めて、正規化のメリットとデメリットを整理しましょう。
正規化のメリット
正規化のメリットを3点ピックアップします。
- データの重複を無くす
- データの整合性を保つ
- メンテナンスを容易にする
データの重複を無くす
複数のレコードに渡り同じデータを繰り返す入力すると、記憶領域を無駄に消費するだけでなく、誤入力によりデータの矛盾が発生する原因になります。正規化によってデータを整理し、重複を排除することで、データベースを効率的に運用できます。
専門用語で「データの冗長性を排除する」という表現をよく使うよ
データの整合性を保つ
データの追加、更新、削除を行う際に、正規化されたデータベースは矛盾が生じにくく、正確なデータを維持しやすいため、データベースの信頼性を高めることができます。
メンテナンスを容易にする
適切に分割されているテーブルは視認性に優れているため、データベースの変更や修正が容易になります。これにより、メンテナンス作業の負担を軽減し、システム全体の運用効率を向上させることができます。
正規化のデメリット
正規化は、データの整合性や効率性を高める上で非常に有効な手段ですが、細かくテーブルを分割しすぎると、データベース全体の構造が複雑化することで全体のパフォーマンスや検索速度にも影響を与えます。また引継ぎを受けた後任者等がデータの関係性を理解するのが難しくなるという一面もあるでしょう。
よって、正規化を行う際には、メリットとデメリットのバランスを慎重に検討しながら、システムの規模や目的に合わせ、適切に設計を行う必要があります。
リレーションシップ
分割したテーブル同士を関連付け、一つのテーブルのように扱うことを「リレーションシップ」といいます。
こちらは実際に各テーブルをリレーションシップ機能で関連付けした様子です。
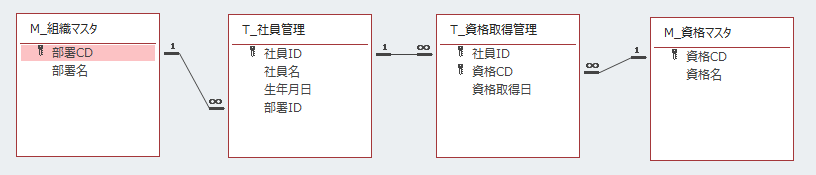
そして、こちらがクエリでデータ表示したものです。

本記事の冒頭で示したサンプルテーブルと同様(部署IDと資格CDは増えていますが)のデータとなっていますが、複数回登場するデータ(社員名の「木村」や「中村」など)は、実データではなく、別テーブルから引用している形です。よって記憶領域を消耗していませんし、手入力ではないため効率性・信頼性も高くなりました。
リレーションシップについては、こちら↓の記事で詳しく解説していますので、ぜひご覧ください。

まとめ
テーブル設計において避けて通れない正規化について解説しました。最初は少し難しく感じるかもしれませんが、一度理解してしまえば、自然と正規化の考え方を取り入れたテーブル設計ができるようになるでしょう。

